Three Years of Running a Link Blog – Visualized
In the early 2010 I decided to track how much time I waste
From that moment on I linked to almost every piece of online writing I have read. I also carefully tagged it and then published on a blog called Supervolatile.com – a name reflecting the state of human memory flooded with internet trivia. Fortunately, it wasn’t my goal to reduce the amount of time I spend reading online, but rather to measure that time. If I kept the former goal, it would be an utter failure.
Spending three years just to track my readership habits clearly wasn’t enough. I also wanted to find out if there are any meaningful trends behind it. Can several hundreds of data points reveal some deep truth about my interests? Spoiler alert: not really. Nevertheless, I decided to put together a visualization of all the articles and topics I have read in that period, all grouped by six major meta tags.
It is also a take on presenting a large blog archive (almost 1500 posts) on one page, in an interactive, browsable format.
My initial goals went mostly unfulfilled. I only know that I spent a LOT of time reading online, and that didn’t even include the extra effort to keep track and visualize all that content. I also didn’t reach the enlightenment of the true understanding of my own interests. But one thing did work out: forcing yourself to write even a short comment about a read article makes you more likely to remember that article. It may also turn you into an inexhaustible source of random trivia during lunch conversations – as it has happened to me. You have to decide for yourself if that’s worth such efforts.
So here is the data, and it is up to you to draw any conclusions from it. Other than the obvious conclusion that I clearly have too much time and of course, I do use a data management software (view it here).
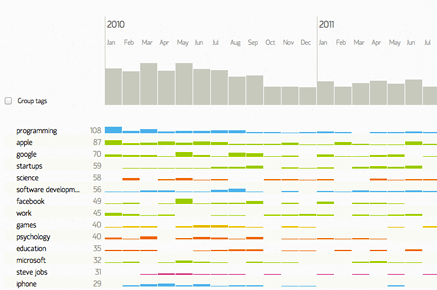
The code I used to create this visualization is available on GitHub.
Brush
Man..
You’re really persistent. The only think i’ve tracked like that for the last 3 years are the books/audiobooks i’m reading. :)
Michal Szklanowski
No one said big data is easy… :)